Use merge to split data into multiple tables
I wish over the years, as I’ve learned various tricks, that I had saved where/who I got it from so that I could credit back later on. I guess I never expected to have a blog one day.
This is a trick I’ve only had to use a few times over the years, but I was going though some code I had written a while back which uses this technique and I thought it would be fun to write about it.
Here’s the scenario
You’ve got a table with data you need to split into two tables. Table1 has an identity primary key (PK), Table2 has a foreign key (FK) pointing back to the PK on Table1.
Take a second and think about how you would you do this.
The basic idea is you need to insert records into Table1, somehow get their identity values, then insert those identity values into the FK column when you perform your insert into Table2.
I can think of a few ways to do it…
Insert and select. Insert into Table1. Select the records you just inserted back from Table1 to get the new identity values. Use some sort of natural key to join those records back to the source, then perform the insert into Table2. This is a little janky because you risk causing duplicates or bad matches if your natural key isn’t as unique as you thought it was. It’s also not very efficient because you have to hit Table1 twice, once for the insert, then again for the select.
Insert with output clause. Basically the same idea as above, except instead of performing the select, you use an OUTPUT...INTO clause on your insert.
Use a sequence. Create a sequence object. Assign the sequence to the PK column on Table1 using a default constraint. Now you can use your sequence to generate the values prior to inserting into both tables.
Add a helper column to the destination table. Create some kind of “helper” column on Table1 which stores a unique ID from the source table. Combine this with using the “insert with output clause”, and it makes for an interesting solution. Now you can return both the new identity value and the original key from the source allowing you to easily map the new identity back to the source data to be later used with your insert into Table2.
Unless you have access to make schema changes, some of these may not be good solutions for you. You can also run into issues when trying to re-query your inserted data if you don’t have a reliable and efficient way to get it back, especially if it’s a large table and not indexed in a way useful to you.
In comes the merge statement
MERGE might sound like an odd tool to use for this, especially since you’re only planning to do an insert, no updates or deletes. The thing that makes it awesome is the OUTPUT clause. I know what you’re thinking…“but the output clause is supported on insert statements too”…yes…you’re right; but when using merge, you get something a little extra with the OUTPUT clause.
When using the OUTPUT clause with a MERGE statement, not only do you get access to the inserted/deleted columns of the destination table, but you also have access to columns in the source table. This is not something you can do with an OUTPUT clause on a simple INSERT.
Setup the demo
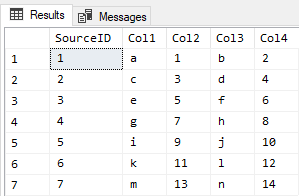
Create some sample data. This is the source table we want to split across two tables:
CREATE TABLE #Source (
SourceID int IDENTITY(1,1),
Col1 varchar(10),
Col2 varchar(10),
Col3 varchar(10),
Col4 varchar(10),
);
INSERT INTO #Source (Col1, Col2, Col3, Col4)
VALUES ('a', '1','b', '2')
, ('c', '3','d', '4')
, ('e', '5','f', '6')
, ('g', '7','h', '8')
, ('i', '9','j','10')
, ('k','11','l','12')
, ('m','13','n','14');
Set up the schema (sorry, can’t use temp tables for this one, they don’t support FK’s):
CREATE TABLE dbo.Table1 (
Table1ID int IDENTITY(1,1),
Col1 varchar(10),
Col2 varchar(10),
PRIMARY KEY CLUSTERED (Table1ID),
);
CREATE TABLE dbo.Table2 (
Table1ID int,
Col3 varchar(10),
Col4 varchar(10),
FOREIGN KEY (Table1ID) REFERENCES dbo.Table1 (Table1ID),
);
Lastly, we need a table we can use for temporarily storing the old and new identity values.
CREATE TABLE #IDs (
SourceID int,
Table1ID int,
);
The key to making this whole thing work
MERGE INTO dbo.Table1 t
USING #Source s ON 1 = 0
WHEN NOT MATCHED BY TARGET
THEN INSERT (Col1, Col2) VALUES (s.Col1, s.Col2)
OUTPUT s.SourceID, Inserted.Table1ID INTO #IDs (SourceID, Table1ID);
The result of this query is that now Table1 is populated with #Source.Col1 and #Source.Col2, it generated identity values for each record (Table1.Table1ID). It then returned (OUTPUT) the #Source.SourceID and the Table1.TableID columns and insert them into our ID mapping table #IDs. All of that being done in a single statement.
Let’s go through this. For the most part, it’s just a simple boring merge statement. We want to merge data from #Source into Table1. The two pieces here that make this work are…
First, we’ve hard coded 1 = 0 in for the join logic. This is to force the merge to always jump to the WHEN NOT MATCHED BY TARGET part of the merge, since all we care about is performing inserts.
Second, we’ve added an OUTPUT statement returning both the original identity PK value from #Source as well as the new identity value from Table1. Thus giving us a perfect mapping of our source data to the new identity values!
Now that we’ve got Table1 populated, lets finish it up and populate Table2 using our ID Mapping table to include the FK values.
INSERT INTO dbo.Table2 (Table1ID, Col3, Col4)
SELECT id.Table1ID, s.Col3, s.Col4
FROM #Source s
JOIN #IDs id ON id.SourceID = s.SourceID
Now verify your results:
SELECT t1.Table1ID, t1.Col1, t1.Col2, t2.Col3, t2.Col4
FROM dbo.Table1 t1
JOIN dbo.Table2 t2 ON t2.Table1ID = t1.Table1ID
Et Voilà!
For those interested, here’s what the execution plan looks like:
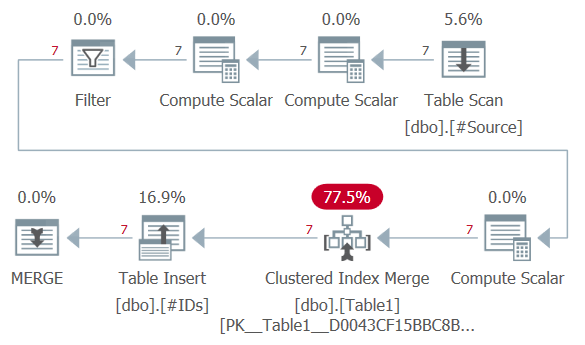
If you want to know more about the details of a merge execution plan, check out this blog post from Hugo Kornelis explaining the details of a merge execution plan from his “plansplaining” series.